
このブログ記事のシリーズでは、機械学習、とくに生成 AI と法的な問題について述べます。全 3 回を予定しており、今回はその 1 回目です。
はじめに
深層学習がブームから実運用へとフェーズが変わり、機械学習は一般的な技術のひとつとなりつつありますが、ChatGPT を初めとした生成 AI の出現によって機械学習モデルの利用がさらに広がっています。どのような用途に用いられているのかは先のブログポストシリーズで扱っているので、そちらをご参照ください。
生成 AI については世間の注目度も非常に高いです。これまでの機械学習モデルはさまざまなものをスコア付し、情報を付加するのが目的でした。一方、生成 AI はこれまで人手で作成するのが主流だった、見たり読んだりするための画像や文章を直接生成します。従来のものと比べて出力がより身近なものとなっており、生成 AI の影響は従来のAIブームと比較してもさらに大きくなっています。
また、ChatGPT のような使いやすいインターフェイスが提供されているため、利用者は急拡大しています。一方で、生成 AI が新たな議論を読んでいることも事実です。とくに、生成 AI の構築・運用で用いられるデータの利用について、さまざまな観点から議論が進行しています。
この記事では生成 AI に関連して議論される、法的・倫理的な問題について検討します。この分野は現在も議論が進行中ですが、議事録など現在オープンになっている情報をもとに、著作権を中心にまとめます。
なお、このシリーズでは日本国における状況について主に述べていきます。
生成AI以前の著作権と機械学習
この記事では生成 AI 以前の状況について確認していきましょう。以降では画像の分類を行ったり、文章の感情分析を行うような機械学習モデルを考えます。
機械学習モデルの訓練のためにデータを利用することは、これまでは問題ないとされていました。これは著作権法でも認められているのですが、どのような記述により機械学習のためのデータ利用が認められているのか、また、その記述はどのような理由で存在するのか確認しましょう。
機械学習のためのデータの利用
機械学習のためのデータ利用は2段階に分けて考える必要があります。1段階目は機械学習モデルを作る訓練で、2段階目はモデルにデータを与えて結果を得る推論です。次の資料は文化庁のもので生成 AI を念頭とした表記となっていますが、分類などの一般的な機械学習でも同様です。
AI と著作権 p.27 https://www.bunka.go.jp/seisaku/chosakuken/pdf/93903601_01.pdf
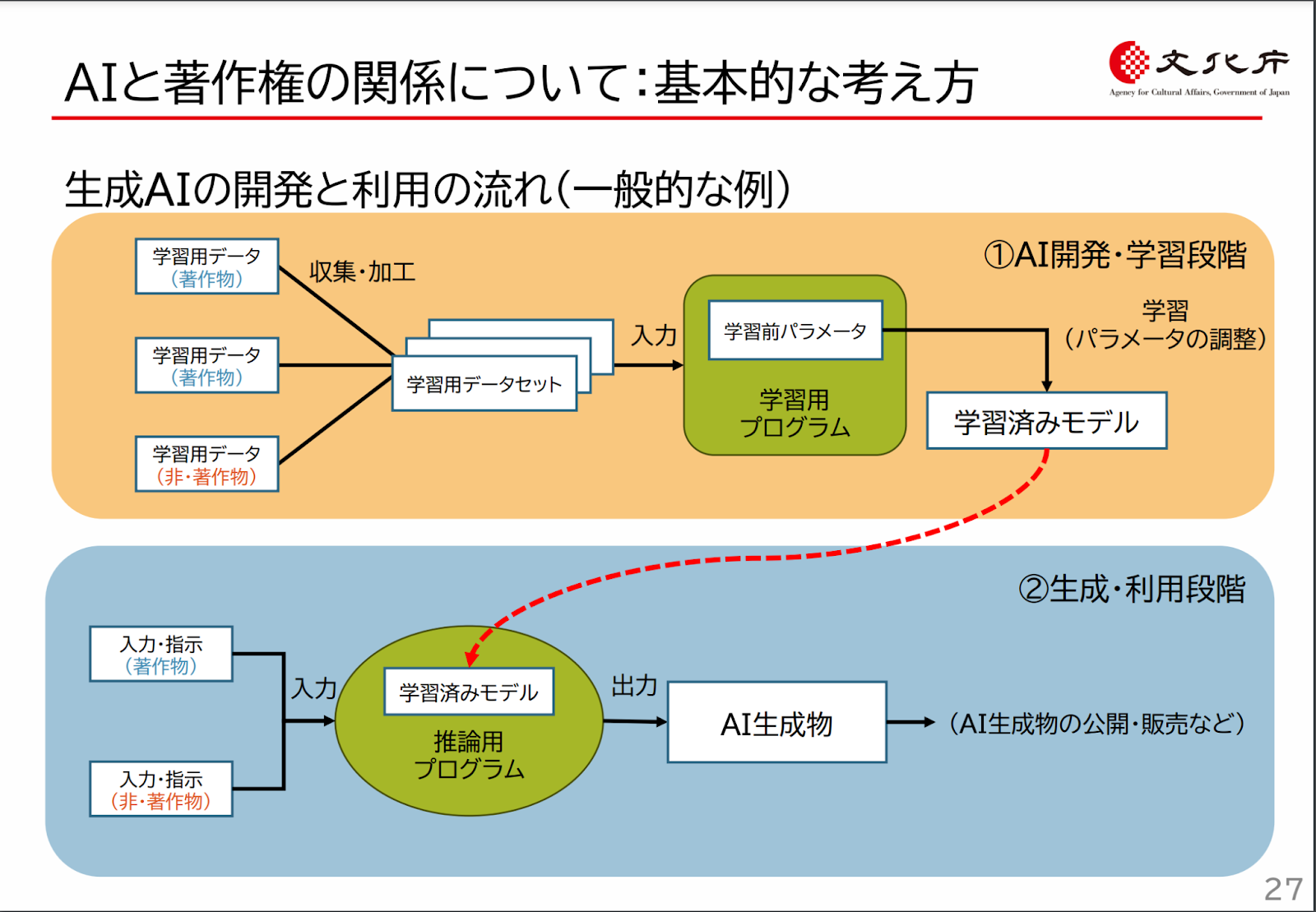
機械学習における訓練のためのデータ利用は著作権者に許可を得なくても可能だとされてきました。これは著作権法第 30 条の 4 によって保証されます。著作権法をそのまま引用しましょう。
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
著作権法 https://elaws.e-gov.go.jp/document?lawid=345AC0000000048
この例外規定の対象となるための重要な条件は次の2つです。
- 当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合
- 情報解析の用に供する場合
機械学習モデルの訓練はこの条件を満たすため、著作物を利用できるとされてきました。前者の条件については第2回で詳しく触れますが、後者について具体例をもとに確認しましょう。
「情報解析の用に供する場合」とは
では、「情報解析の用に供する場合」とは具体的にどのようなものなのでしょうか。以降では Web 検索と機械学習モデルの2つの事例について、それぞれ述べていきます。
Web 検索サービスの場合
Google 検索や Bing 検索 のような Web 検索サービスを提供することを考えましょう。
Web サイトを広く検索できるようなサービスを提供するためには Web サイトを広くクローリングして各ページのデータを収集し、データベースを作成する必要があります。このデータベースの作成は「情報解析の用に供する場合」に該当するとされています。
もし第 30 条の 4 のような例外規定がなかったらどうなるでしょうか。Web サイトをクローリングして得たサイトの情報は、もちろん Web 検索サービスの提供者が作成した著作物ではありません。このため、例外規定がない場合、Web 検索のようなサービスは著作権法により提供できなくなってしまいます。もちろん、著作者ひとりひとりに許可を取ればそのようなことも可能ですが、Web の広大な世界においてそのようなオペレーションは現実的ではないでしょう。
また、Web 検索サービスに著作物を利用してもらうことは、著作者にとってもメリットがあると考えられます。もしこのような検索サービスがないと、Web でコンテンツを公開したとしても、エンドユーザーがそれを発見することは至難の業でしょう。せっかく作成した著作物も、エンドユーザーに届きにくくなってしまいます。
もちろん、管理用コンソールへのログインページなど、検索サービスには表示したくないようなページも存在するでしょう。そのような場合に対応するための方法が検索サービスでは提供されています。検索サービスに掲示されたくない場合は、robots.txt という標準的な方法により、検索サービスへの表示について著作権者からの意思表示が可能となっています。
このようなユースケースは著作者にとっても有益と考えられるため、「情報解析の用に供する場合」として保護されています。
機械学習の場合
次に、機械学習を用いた画像認識サービスを考えます。ここでは画像認識として、製造物のキズの検出のような特定画像ではなく、有名な建物、ランドマークを検出するようなサービスを考えます。
このような画像認識サービスを提供するためには、ImageNet のように広くデータを収集して、写真とそこに写っているランドマークが対になったデータセットを作成する必要があります。機械学習モデルの訓練過程では、このデータベースから画像とランドマークの対応関係を学習させ、モデルを作成します。
機械学習の訓練のために要求される画像の数は尋常ではなく、自分で撮影した画像だけでデータセットを構築することは現実的ではありません。そのため、一般的に Web サイトをクローリングして得たものも利用されます。このモデルの訓練用のデータベースの作成と、モデルの訓練は「情報解析の用に供する場合」に該当するとされています。
第 30 条の 4 のような例外規定がないとどうなるでしょうか。クローリングして得られた画像データは、画像認識サービスの提供者の作成した著作物ではないものが含まれるため、上記のようなサービスの開発自体ができなくなってしまいます。また、画像に「ランドマーク」という付加的な情報を付け加えるサービスでしかないため、写真家に代表される著作者の利益を著しく損害することは、想定しにくいと言えるでしょう。
少し別の観点として、イノベーションへの悪影響も考えられます。機械学習の技術は発展が続いていますが、日本の法律によりデータセットを構築できない場合、日本におけるイノベーションを阻害してしまうことにも繋がりかねません。
上記のような理由から、機械学習への応用も認められているといえます。
生成 AI と従来の機械学習モデルの差異
ここまでで、Web 検索や従来の機械学習モデルの訓練において著作物の利用が許されていることを述べてきました。
第 30 条の 4 のような例外規定ができた背景には、上記のようなユースケースにおいて、著作者の利益を著しく損害することは考えにくいと想定されたことがあります。検索サービスの場合、著作物へのアクセスを容易にするため、著作物はより利用されやすくなり、著作者の利益につながることが考えられます。また、機械学習サービスの場合、著作物に付加的な情報を与えるのみなので、直接的な競合となることは考えにくいでしょう。
しかし、生成 AI は違います。生成されるのは文章や画像といった、著作物と同じフォーマットであるため、著作者の直接的な競合になります。生成 AI により生成される画像は、基本的には訓練データセットと同じようなデータになることも、生成 AI を著作者の直接的な競合にしやすくしていると言えます。
ではどのような場合に著作権の侵害が認められるのでしょうか?次回は著作物の侵害になるケースとならないケースについて検討します。
注意
本ブログ記事は2023年12月末時点で入手可能な情報に基づいており、可能な範囲で正確になるよう努めていますが、正確性を保証するものではありません。また、AIと著作権について法的助言を含めた包括的な記述をめざすのではなく、テクノロジー企業の視点に基づいて限定的な側面を記述しています。
本ブログ記事内の情報を利用することで生じたいかなるトラブル、損失、損害に対しても、弊社は一切責任を負いません。個々の事例の判断は、専門家に調査を依頼する等、個人の責任において行ってください。


