
このブログ記事のシリーズでは、機械学習、とくに生成 AI と法的な問題について述べます。全 3 回を予定しており、今回はその 2 回目です。
前回は生成 AI 以前の機械学習と著作権について、どのように整理されているのか見てきました。今回はそもそもどのような場合に著作権の侵害とみなされるのか確認しましょう。
著作権の侵害となるケースとならないケース
著作権の侵害となるかどうか、事前に判断することは極めて困難です。事前の判断が困難な理由として次の2つが挙げられます。
- 著作権の侵害となるかどうかは個別の事例による判断が大前提となっていること
- 著作権の保護となる対象が、一般の認識と必ずしも一致しないこと
前者について、著作権の侵害となるかどうか、画一的な基準が存在しないことが事前の判断を困難にしています。後に具体例で確認するように、著作権の侵害となるかどうかは個別の事例を元に総合的な判断がくだされ、非専門家が判断を下すことは困難です。単に見た目が似ている、同じ言葉を使っているだけでは侵害とは断定できないことには注意しましょう。
また、著作権の保護となる対象は、一般の認識と必ずしも一致しません。ある事例が別の著作物の著作権を侵害しているかどうか確認するためには、次の観点からの検討が必要となります。
- 著作物であること
- 類似性の有無
- 依拠性の有無
加えて、機械学習の訓練に用いるための例外規定である、30 条の 4 を適用するためには「享受」についても知っておく必要があります。以降でこれらの概念について確認していきましょう。
著作物とは
著作権を主張するためには、その作品が著作物である必要があります。何かを参照して作られたものだとしても、それが著作物としての要件を満たさなければ、もともと著作権が発生しないので著作権の侵害とはなりません。
著作権法における著作物の定義は次のとおりです (第2条)。
- 思想又は感情を
- 創作的に
- 表現したものであつて、
- 文芸、学術、美術又は音楽の範囲に属するものをいう。
文芸、学術、美術などがあげられていますが、絵画、小説以外にもソースコードはこの定義に含まれます。
一方で、著作物に関連したものなら何でも保護されるわけではなく、たとえば画風やアイデアは保護の対象に含まれません。これは著作権法で保護する対象が表現そのものとなっており、画風やアイデアを流用したほかの創作を妨げないようになっています。
また、事実の列挙や単なる数値も著作物には含まれません。たとえば、あるデータセットから重回帰分析を行って得られた重みは、データセットから作成されたものではありますが、おそらく著作物として主張することは困難だと思われます。
このため、表現として漫画のあるコマでほかの漫画家の画風をまねて創作を行うことは、基本的には問題ないといえます。ただし、次に述べる類似性と依拠性については注意が必要です。
類似性
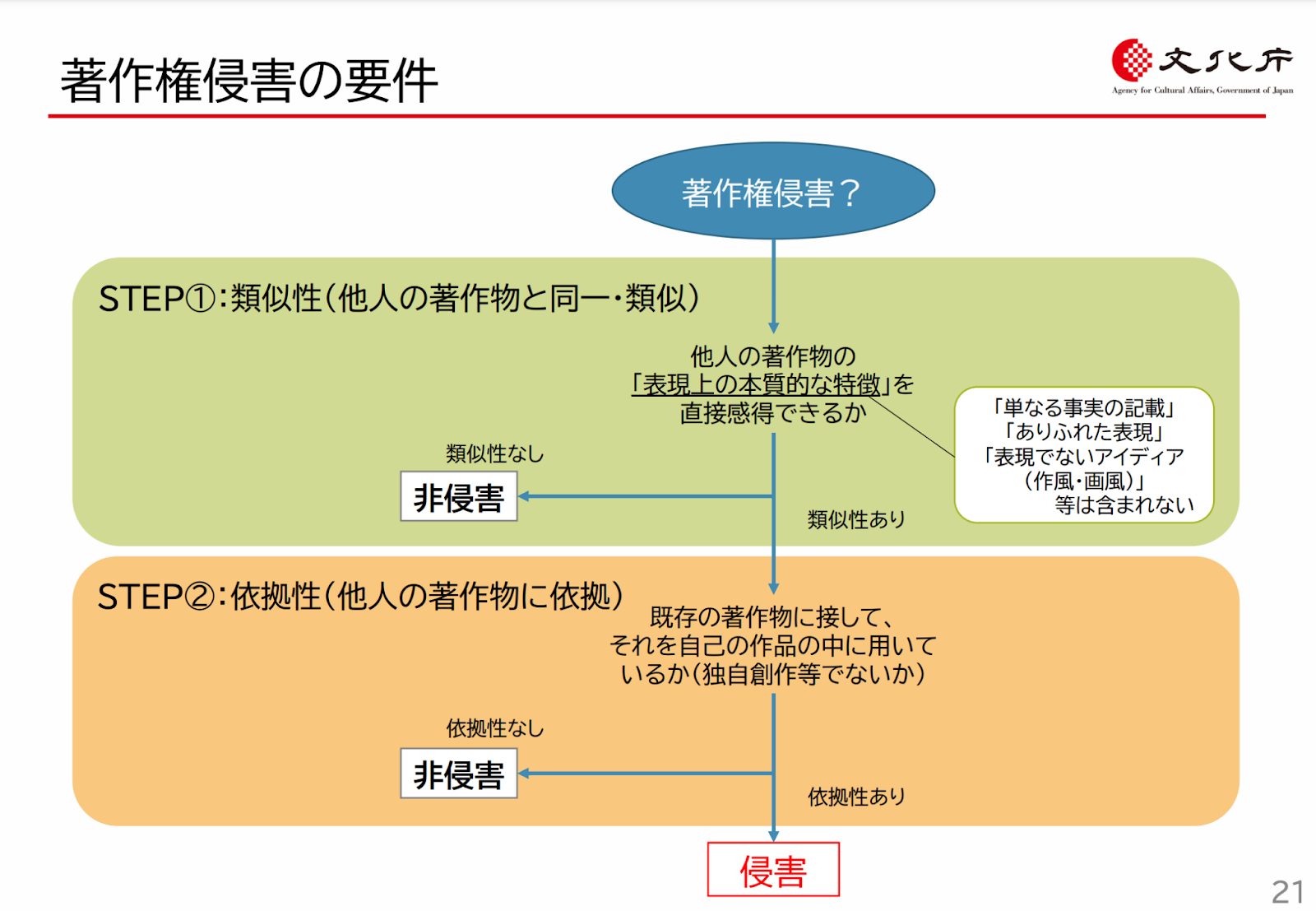
類似性は「後発の作品が既存の著作物と同一、又は類似していること」を言います。
類似性は判例において「表現上の本質的な特徴を直接感得することのできる」ことが必要とされています。このため、画風やアイデアといった、著作権の保護の対象とはならない部分が共通していても著作権の侵害とは必ずしもなりません。
また、特徴が単に似ているだけでも侵害とは断定できません。有名な事件として「けろけろけろっぴ事件」というものがあります。これは、サンリオのけろけろけろっぴというキャラクターと、別のカエルのイラストの類似性が問題となった事件です。
判決(東京高判平成13年1月23日)では類似性が否定されました。その際には以下のように述べられています。
擬人化されたカエルの顔の輪郭を横長の楕円形という形状にすること、その胴体を短くし、これに短い手足をつけることは、擬人化する際のものとして通常予想される範囲内のありふれた表現というべきであり、目玉が丸く顔の輪郭から飛び出していることについては、我が国においてカエルの最も特徴的な部分とされていることの一つに関するものであって、これまた普通に行われる範囲内の表現であるというべきである。
実際に添付文章に含まれているイラストを引用すると、次のようなイラストが含まれています。

素人目から見ても、たしかに一部のイラストは似ていると言いたくかもしれません。一方、判決では「普通に行われる範囲内の表現」となっており、類似性は否定されています。
このように、創作的な表現であることの要件はかなり厳しく複雑です。類似性も簡単には判断できないことがこの判例からもわかります。
依拠性
依拠性は「既存の著作物に接して、それを自己の作品の中に用いること」を言います。
ざっくりと言うと、その著作物を知っていたかどうかですが、知っていたかどうかはさまざまな要因から総合的に判断されます。また、「既存の著作物を知らず、偶然に一致したに過ぎない、「独自創作」などの場合」には依拠性がないと判断されます。 (AI と著作権 p.19 https://www.bunka.go.jp/seisaku/chosakuken/pdf/93903601_01.pdf)
また、依拠性の判断においては創作時点の時系列や、「図書館でコピーした」といった行動をもとに判断されるようです。ほかに、透かしや誤字などの元の著作物に含まれる特徴を再現している場合も、依拠性があると判断される根拠のひとつとなります。
ここまでの著作権侵害に関する要件をまとめると次のようになります。
AI と著作権 p.21 https://www.bunka.go.jp/seisaku/chosakuken/pdf/93903601_01.pdf
また、機械学習に用いる場合 (「情報解析の用に供する場合」として第 30 条の 4 の例外規定の適用対象としたい場合) 次の「享受」という概念についても確認が必要です。
享受
もう一度、著作権法第 30 条の 4 によって著作物を利用可能になる条件を確認しましょう。
- 当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合
- 情報解析の用に供する場合
後者の「情報解析の用に供する場合」がどのような場合なのかは前回確認しました。では、前者の条件、とくにその中に現れる「享受させることを目的としない」とはどのような意味なのか確認しましょう。
享受とは「著作物の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為」のことを言います。
AI と著作権によれば、次のような例が「享受」といえる行為として挙げられています。
- 文章の場合、読むこと
- プログラムの場合、実行すること
- 音楽や映画の場合、鑑賞すること
また、享受を目的としない用途であれば、著作権者の経済的利益を害しにくいと考えられます。前回の Web の検索サービスや、古典的な機械学習は享受目的にはなりにくいでしょう。
まず、検索サービスの提供のためのデータベースでは、たしかに著作物やその一部であるタイトルや本文といった情報を、保存し利用しています。しかし、検索対象とすることは「知的・精神的欲求を満たすという効用を得る」とは言えなく、享受が目的ではないと言えるでしょう。
古典的な機械学習モデルの訓練用データセットの作成やモデルの訓練も同様に、享受が目的ではないと言えるでしょう。
例として、イラストから作成された年代を推論するような画像認識モデルを作成することを考えます。このモデルを作成するためには、訓練用のデータセットとして各年代ごとのイラストを収集し、年代ごとに保管し、モデルの訓練で利用することになります。この場合、画像を収集していても、それ自体を鑑賞する目的ではないため、享受が目的ではないと言えるでしょう。
この「享受させることを目的としない」ことを許す背景には、そのような用途は著作権者の経済的利益を害しにくいという考え方があることは今後重要となるので、ここで強調しておきます。
生成 AI について
ここまでに著作権の侵害を判断する要因となる、「元の作品が著作物であること」「類似性」「依拠性」「享受」について見てきました。また、何らかのスコアを出力する通常の機械学習モデルでは、基本的には著作権の侵害とならないこと見てきました。
ここでは、対話を行う生成 AI を対象に、基本的な考え方を確認しましょう。今回は思考実験のため、API を単に利用するのではなく、言語資源を大量に収集し、対話サービスを提供するための機械学習モデルを作成することを考えます。
生成 AI についても通常の機械学習同様に、次の 2 段階で考える必要があります。
- 開発段階: 機械学習モデルの作成
- 生成段階: 文章の作成
AI と著作権 p.27 https://www.bunka.go.jp/seisaku/chosakuken/pdf/93903601_01.pdf
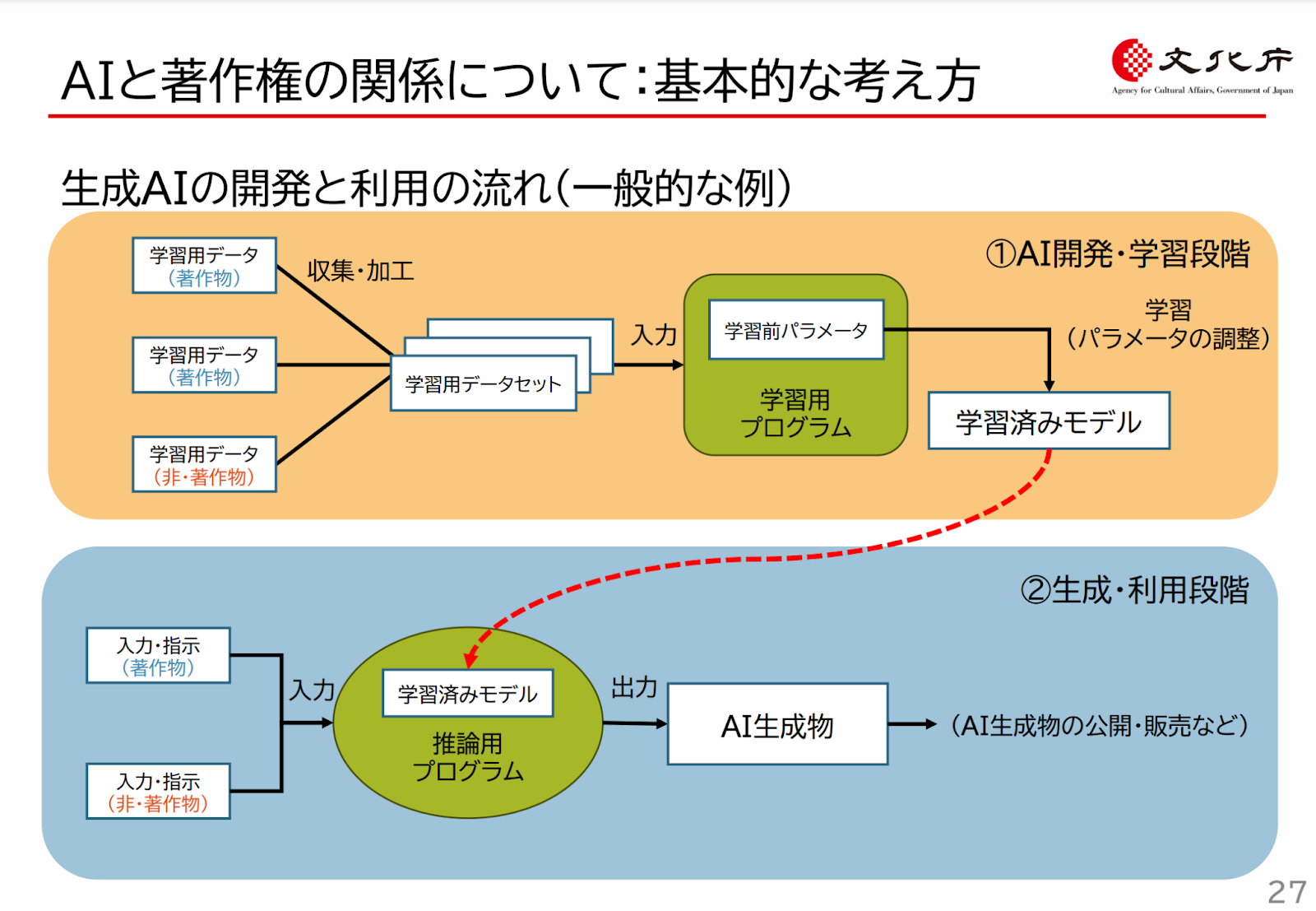
開発段階の基本的な考え方
まずモデルの訓練を行う開発段階についての基本的な考え方ですが、基本的には、享受を目的としない非享受の利用となるでしょう。このため、原則的には著作権者の許諾を必要とせず利用可能になると思われます。
SNS などでは「AI 学習禁止」を掲げられている方もいますが、現状ではあまり意味がないと思われます。例外については第3回で述べます。ただし、次の条件についてはは考慮が必要です。
著作権者の利益を不当に害することとなる場合
データセットの作成において、「著作権者の利益を不当に害することとなる場合」は著作権法第 30 条の 4 の適用対象となりません。
たとえば、機械学習用のコーパスを作成し販売している場合において、そのコーパスをコピーして無断で使うことは、著作権者の利益を不当に害することとなる場合と言えるでしょう。
特定の画像に類似した画像を出力するモデルを作成した場合
特定の文章や画像に、極めて類似した文章や画像を出力するモデルを作成した場合はどうでしょうか。このような場合、そのモデルを配布するために訓練することは、本当に享受に当たらないのか疑問視されるようになってきました。
このケースについては第3回で改めて取り上げます。
生成段階についての基本的な考え方
生成段階について基本的な考え方を確認しましょう。
生成段階では、基本的に通常の人手により作成された作品と同様に判断されます。生成された文章を広く公開するのではなく、私的に利用する場合はとくに問題ありません。広く公開する場合には著作権の侵害のリスクについて検討する必要があります。侵害となるかどうかは「類似性」「依拠性」といった要素について総合的に検討され、判断されることになります。
類似性については人手による作品と同様の判断ができそうです。さきほど確認したように、さまざまな要素を元に総合的に判断することになるでしょう。
依拠性については少し複雑になります。今回考えているケースのように、自分でデータを収集してモデルを作成している場合、訓練したデータセット内に含まれている文章については依拠性があると思われます。
一方、実用上は大規模なモデルをゼロから訓練することはあまりなく、訓練済みのモデルをそのまま用いるか、あったとしてもファインチューニングにとどまるでしょう。この場合、モデルの作成者と文章を生成するエンドユーザーはそれぞれ別々になります。また、エンドユーザーは、訓練したデータセット内にどのような文章が含まれているか知らない場合が想定されます。この場合、依拠性がどのように判断されるかは不透明です。
以上が生成 AI に関する基本的な考え方です。しかし、生成 AI については技術的な進歩も、世の中への浸透も非常に早く、基本的な考え方だけで対応しかねるケースも出てきています。第3回では、そのような基本的な考え方だけでは解決できない課題について考えていきます。
注意
本ブログ記事は2023年12月末時点で入手可能な情報に基づいており、可能な範囲で正確になるよう努めていますが、正確性を保証するものではありません。また、AIと著作権について法的助言を含めた包括的な記述をめざすのではなく、テクノロジー企業の視点に基づいて限定的な側面を記述しています。
本ブログ記事内の情報を利用することで生じたいかなるトラブル、損失、損害に対しても、弊社は一切責任を負いません。個々の事例の判断は、専門家に調査を依頼する等、個人の責任において行ってください。



